《MySQL必知必會》學習筆記九(組合查詢&全文本搜尋)——掌握部分
利用union操作符將多條select 語句組合成一個結果集。
復合查詢:
多數SQL查詢都隻包含從一個或多個表中返回數據的單條select語句。MySQL也是允許執行多個查詢(多條select語句),並將結果作為單個查詢結果集返回。這些組合查詢稱為並(union)或者復合查詢。
兩種基本情況使用組合查詢:
1. 在單個查詢中從不同的表中返回類似結構的數據;
2. 在對單個表執行多個查詢,按照單個查詢返回數據。
組合查詢和多個where條件
多數情況下,組合相同表的兩個查詢完成的工作與具有多個where子句條件的單條查詢完成的工作相同。也就是說,任何具有多個where子句的select語句都可以作為一個組合查詢給出。這兩種技術在不同的查詢中寧性能也是不同,因此,應該試一下這種技術,然後選擇性能更好的查詢。
使用union隻是在各條語句之間放上關鍵字union
select vend_id,prod_id,prod_price from products where prod_price <=5 union select vend_id,prod_id,prod_price from products where vend_id in(1001,1002);
select vend_id,prod_id,prod_price from products where vend_id in
(1001,1002) union select vend_id,prod_id,prod_price from products where
prod_price <=5; // 無關先後順序
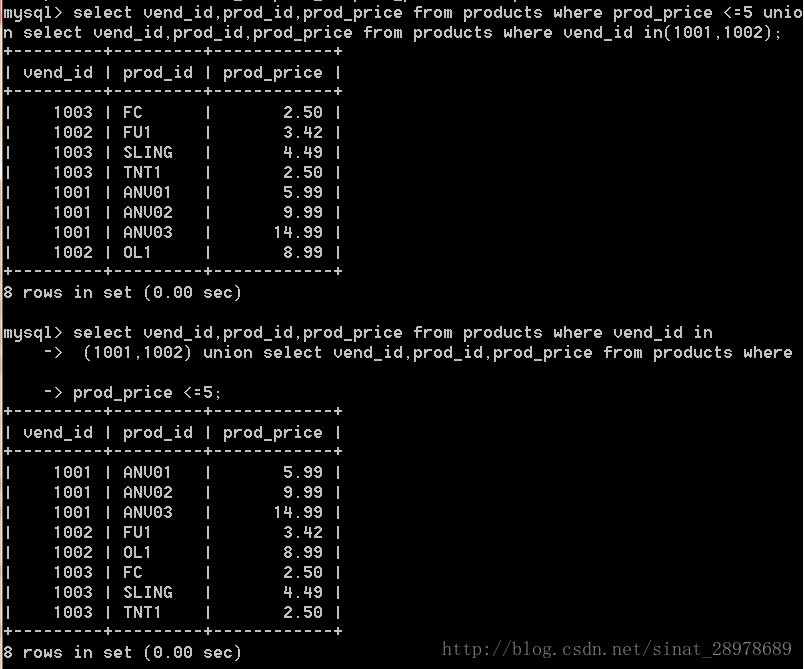
union從查詢結果中會自動刪除重復行,where也是會自動去除重復行
union All 則不會從結果中自動刪除重復行。
組合查詢使用規則:
1.必須由兩條或者兩條以上的select語句組成,語句之間用關鍵字union分隔
2.每個查詢中必須包含相同的列,表達式或聚集函數(順序可以不同)
3.列數據類型必須兼容,類型不必完全相同,但必須是DBMS可以隱含地轉換的類型。
對組合查詢結果的排序
Select 語句的輸出用order by子句排序,在用union查詢時,隻能在最後一條select子句之後使用order by,不允許使用多條order by 子句。
select vend_id,prod_id,prod_price from products where vend_id in
(1001,1002) union select vend_id,prod_id,prod_price from products where
prod_price <=5 order by vend_id,prod_price;
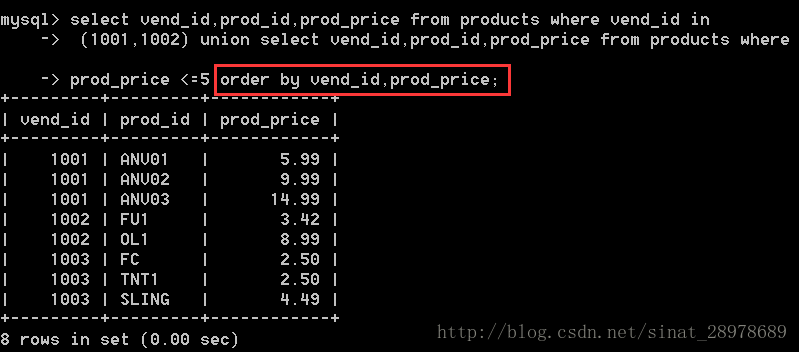
註意:組合查詢可以組合不同的表之間的查詢,但是要保證查詢的返回的列,表達式,或者聚合函數保持一致。
第十八章FULLTEXT&Match()&Against()
全文本搜尋:
並非所有的引擎都支持全文本搜尋,兩個最常用的引擎為MyISAM 和 InnocenceDB,前者支持全文本搜尋後者不支持。如果應用中需要使用全文搜尋功能,則應該記住使用MYISAM引擎。
全文本搜尋&LIKE關鍵字搜尋&正則表達式搜尋
使用like關鍵字或者是利用正則表達式進行搜尋,這些搜尋機制非常有用,但是存在幾個限制:
1.性能—— 通配符和正則表達式匹配通常要求MySQL嘗試匹配表中所有行(而且這些搜尋極少使用表索引)。因此,由於被搜尋行數不斷增加,這些搜尋可能非常耗時。
2.明確控制——-使用通配符和正則表達式匹配,很難(而且不總是能)明確地控制匹配什麼和不匹配什麼。
3.智能化的結果——-雖然基於通配符和正則表達式的搜尋提供瞭非常靈活的搜尋,但他們都不能提供一種智能化的選擇結果的方法。
所有這些限制,以及更多的限制都可以使用全文本搜尋來解決。在使用全文本搜尋時,MySQL不需要分別查看每個行,不需要分別分析和處理每個詞。MySQL創建指定列中各詞的一個索引,索引可以根據針對這些詞進行。這樣,MySQL可以快速有效的決定那些詞匹配(那些行包含他們),哪些詞不匹配,它們匹配的頻率,等等
使用全文本搜尋
使用全文本搜尋,必須索引被搜尋的列,而且要隨著數據的改變不斷地重新索引。在對表進行適當的設計後,MySQL會自動進行所有的索引和重新索引。在索引之後,select可與Match()和Against()一起使用以實際執行搜尋。
設定全文本
一般是在創建表時啟動全文本搜尋。Create Table語句接受 FULL text子句,她給出被索引列的一個逗號分隔列表。
mysql> CREATE table productnote(
note_id int not null auto_increment,
prod_id char(10) not null,
note_date datetime not null,
note_text text null,
PRIMARY KEY(note_id),
FULLTEXT(note_text)
) engine=MyISAM;
// MySQL根據子句FULLTEXT(note_text)的指示對它進行索引,如果索引多個列,逗號隔開,在設定之後,MySQL自動維護該索引,在增加,更新或者刪除行時,索引隨之自動更新。
註意:
FuLLText 索引關鍵字一般在創建表時指定FullText,或者在稍後指定(在這種情況下所有已有數據必須立即索引)
不要在導入數據時使用 fulltext, 更新索引要花時間,雖然不是很多,但畢竟要花時間,如果正在導入數據到一個新表,此時不應該啟用fulltext索引,應該首先導入所有數據,然後在修改表,設定fulltext。這樣有助於更快地導入數據(而且使索引數據的總時間小於在導入每行時分別進行索引所需要的總時間)
使用全文本搜尋
select note_text from productnotes where Match(note_text) against(‘rabbit’);
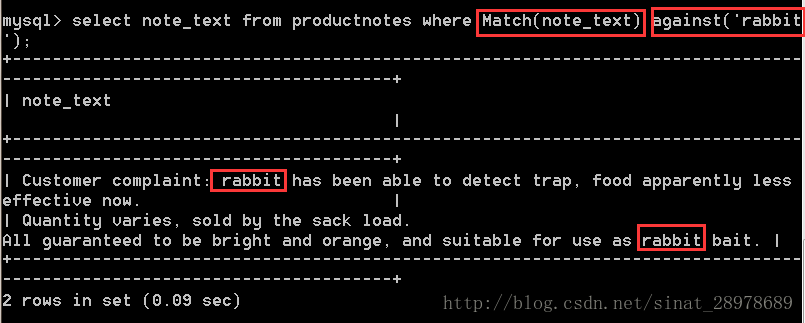
註意:
1、使用完整的Match() 傳遞Match()的值必須與FULLTEXT()設定中的相同。如果指定多個列,則是必須列出它們(而且次序正確)。Against()傳遞所要檢索的內容
2、使用索引進行全文搜尋,返回以文本匹配的良好程度排序的數據。兩行都包含詞robbit,但是包含詞rabbit作為第三個詞的行的等級比作為第二十個詞的行高,這很重要。全文搜尋的一個重要的部分就是對結果排序。具有較高等級的行先返回。而利用like則不具備這種排序效果。
3、搜尋不區分大小寫,除非使用關鍵字Binary。
使用like子句完成相同工作(圖片對比):
select note_text from productnotes where note_text like ‘%rabbit%’;
![]()
演示排序如何工作:
select note_text,MAtch(‘note_text’) against(‘rabbit’) as rank from productnotes;
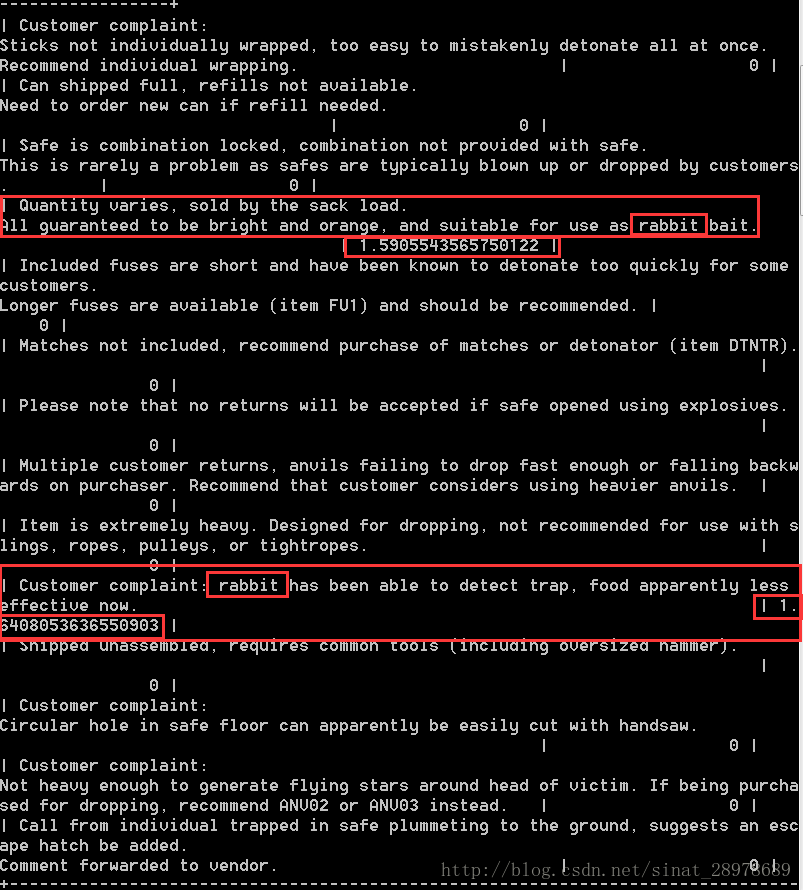
解釋:
在select而不是where子句中使用Match()和Against()。這使所有航都被返回(因為滅有where子句)。Match()和Against()用來建立一個計算列,此列包含全文本搜尋計算出的等級值。等級由MySQL根據行中詞的數目、唯一詞的數目、整個索引中詞的總數以及包含該詞的行的數目計算出來。正是這樣,不包含rabbit的行等級為0(這個原因導致不被前一例子中的where子句所選擇)。確實包含詞rabbit的兩個行每行都有一個等級值,文本中詞靠前的行的等級值比詞靠後的行的等級值高。
總結
說明瞭全文本搜尋時如何排除行(排除那些等級為0的行),如何排序結果(按等級以降序排序)。如果指定多個搜尋項,則是包含多數匹配詞的那些行將具有比包含較少詞(或僅有一個匹配)的那些行高的等級值。全文本搜尋提供瞭簡單的LIKE搜搜不能提供的功能。而且,由於數據是索引的,在數據比較大的時候,全文本搜尋還是相當快的。
使用擴展查詢 with query expansion
在使用擴展查詢時,MySQL對數據和索引進行兩遍掃描來完成搜尋。
首先,進行一個基本的全文本搜尋,找出與搜尋條件匹配的所有行;
其次,MySQL檢查這些匹配行並選擇所有有用的詞
然後MySQL再次進行全文本搜尋,這次不僅使用原來的條件,而且還是用所有有用的詞。
擴展查詢在MySQL4.1.1中引入。
利用擴展查詢,能找出可能相關的結果,即使他們並不精確包含所查找的詞。
(有沒有感覺很類似百度搜尋)
select note_text from productnotes where Match(note_text) against (‘anvils’);
select note_text from productnotes where Match(note_text) against (‘anvils’ with query expansion);
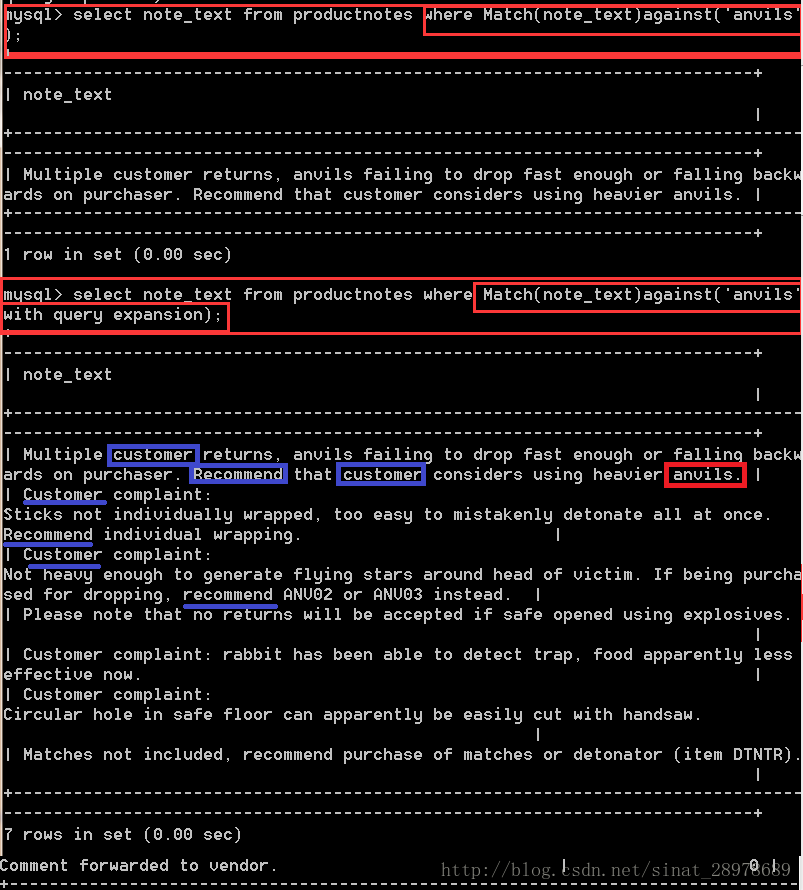
解釋:返回七行,第一行包含anvils,因此等級最高,第二行與anvils無關,但是因為它包含第一行中的兩個詞(customer 和 recommend) ,所以也被檢索出來,第三行也包含這兩個相同的詞,但他們在文本中的位置更靠後且分開得更遠。因此也包含,且等級為第三,第三行確實沒有涉及anvils(按他們的產品名)
查詢擴展極大的增加瞭返回的行數,但這樣也增加瞭你實際不想要的行的數目。
佈爾文本搜尋
以佈爾方式。可以提供關於如下內容的細節:
1.要匹配的詞;
2.要排斥的詞(如果某行包含這個詞,則不返回改行,即使包含其他指定的詞,也被排斥掉);
3.排列提示(指定某些詞比其他詞更重要,更重要的詞等級更高);
4.表達式分組;
5.另外一些內容;
註意:佈爾方式不同於迄今為止使用的全文本搜尋語法的地方在於,即使沒有設定fulltext索引,也是可以使用的,但這是一種非常緩慢的操作(性能會隨數據量的增加而降低)。
select note_text from productnotes where Match(note_text) against(‘heavy’
in boolean mode);
// 註意 此全文本搜尋檢索包含heavy的所有行,其中使用瞭關鍵字 IN BOOLEAN MODE ,但是實際上沒有指定佈爾操作符,因此,此結果與沒有指定佈爾方式的結果相同。。考慮為什麼?

select note_text from productnotes where Match(note_text) against('heavy-rope*' in boolean mode);
// 匹配heavy 但排除任何以rope開始的詞。
select note_text from productnotes where Match(note_text) against('+rabbit +bait' in boolean mode);
//匹配 包含詞rabbit 和 bait 的行
select note_text from productnotes where Match(note_text) against('rabbit bait' in boolean mode);
// 匹配 包含詞rabbit 或bait 的行[至少有一個]
select note_text from productnotes where Match(note_text) against( '“rabbit bait” ' in boolean mode);
//匹配短語rabbit bait 的行 **註意引號區別於上**
select note_text from productnotes where Match(note_text) against('>rabbit 排序而不排列,在佈爾方式中,不按照等級值降序排序返回行。全文本搜尋的使用說明(重點)
1. 在搜尋全文本數據時,短詞被忽略且從索引中排除。短詞設定為那些具有3個或3個一下字符的詞(如果需要,數目可以更改)。
2. MySQL帶有一個內建的非用詞(stopword)列表,這些詞在索引全文本數據時總是被忽略,如果需要,可以覆蓋這個列表(參考MySQL文檔)。
3. 許多詞出現的頻率很高,搜尋他們沒有用處,因此MySQL規定瞭一條50%規則,如果一個詞出現在50%以上的行中,則將它作為一個非用詞忽略。50%規則不使用in boolean mode。
4. 如果表中的行數少於3行,則全文本搜尋不返回結果,(因為每個詞或者不出現,或者至少出現在50%的行中)。
5. 忽略詞中的單引號。Don’t 索引為dont。
6. 不具有詞分隔符(包括日語和漢語)的語言不能恰當地返回全文本搜尋結果。
7. 僅在MYISAM資料庫引擎中支持全文本搜尋。
8. 沒有鄰近操作符 鄰近搜尋時許多文本搜尋支持的一個特性。他能搜尋相鄰的詞。但是MySQL全文本搜尋現在暫時不支持鄰近操作符。