架構設計:系統存儲(7)——MySQL資料庫性能優化。
4、影響SQL性能的要素
MySQL資料庫的性能不止受到性能參數和底層硬件條件的影響,在這兩個條件一定的情況下,開發人員對SQL語句的優化能力更能影響MySQL資料庫的性能。由於MySQL中不同資料庫引擎對SQL語句的處理過程不盡相同,所以對SQL語句的優化就一定要首先確定使用的資料庫引擎的類型。例如MyISAM引擎中統計某一個數據表的總行數時,隻需要讀取出已保存好的數據總行數就OK瞭。但InnoDB引擎要完成這個動作,就必須進行table scan/index scan,而是否為被掃描的字段創建瞭索引又直接影響瞭掃描速度。本文我們和讀者一起來討論一下InnoDB數據引擎下SQL語句常見的工作方式和優化規則。
4-1、索引
我們都知道無論使用哪種主流的關系型資料庫,為SQL查找語句所依據的字段創建索引要比不創建索引時的性能高出幾個數量級(當然這也要看SELECT查詢語句的具體寫法)。那麼為什麼會出現這樣的情況呢?我們又依據什麼樣的原理來創建資料庫的索引呢?本小節將首先為讀者進行原理性描述。
4-1-1、B樹
同樣由於本文的定位,所以我們並不會討論怎樣使用腳本創建索引等基本操作問題。而是直接進行InnoDB資料庫引擎中索引原理的講述。InnoDB中資料庫字段的索引采用樹結構進行組織,這種樹本質上是為瞭解決數據檢索問題的平衡N階樹,又被稱為B樹。B樹及其變體是大學《數據結構》課程中的基礎知識,本人雖然工作許多年但始終對《數據結構》這門課程中的主要知識爛熟於心,並認為它和《 離散數學》一樣已經成為筆者大學時期學習過的,對筆者實際工作幫助最大的兩門課程。
為瞭幫助讀者回憶起B樹及其變體的基本結構,也為瞭後續內容能夠正常鋪開。我們非常需要使用相當的篇幅對它進行介紹。那麼首先使用下圖回答樹結構的幾個基本概念:節點、深度、子樹等。
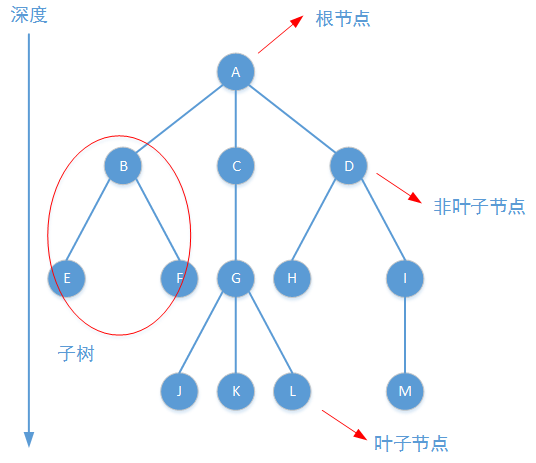
B樹是一顆平衡的多叉檢索樹,它具有以下性質:
所謂檢索樹是指這樣的樹:樹中任意非葉子節點A作為根節點的子樹,其左子樹上節點中的元素值均小於或等於節點A中元素的值;其右子樹上節點中的元素值均大於或等於節點A中元素的值。檢索樹又稱為排序樹、有序樹,如果將檢索樹降維成表結構則同樣可以使用二分查找法進行節點檢索,且時間復雜度基本不變。
如果不加任何構造限制,那麼在樹結構中檢索元素的時間復雜度可能為O(n)。這顯然失去瞭檢索樹的意義,如果一顆檢索樹能夠保證樹的高度H限制在節點數N的對數階范圍內(H=O(logn)),這樣的檢索樹就稱為平衡樹。在編程實踐中隻要保證樹中任意兩個子樹深度差的絕對值不大於1,就可以保證前述條件成立。另外B樹中對深度差絕對值做瞭更嚴格的規定,即所有葉子結點都位於同一深度。
一顆B樹的非葉子節點能夠最多關聯的子節點數量稱為階數。B樹中的階數至少為3,因為當階數為2時B樹進行節點分裂就可能會出現某葉子節點沒有任何元素的情況。
樹中每個非根節點所包含的元素個數 j 滿足:(N/2) – 1 <= j <= N – 1,其中N表示B樹的階數。例如階數為3的B樹每一個非葉子結點能夠存儲的元素個數可能為 0個、1個和2個(但0個元素沒有任何檢索意義,還會造成樹中任意兩個子樹深度差的絕對值改變)。
樹中一個節點可關聯的子節點數量比以上文字中提到的元素最大個數多1。也就是說階數為3的B樹每個節點最多可關聯3個子節點。
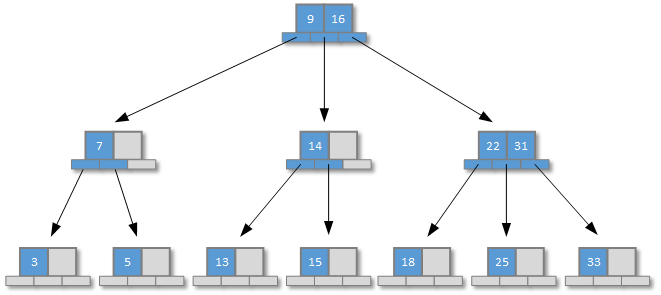
上圖展示瞭一顆3階B樹,它的每個節點最多可以有3個子節點,並且每個子節點中最多有2個元素。可以觀察到B樹滿足檢索樹的基本規則:凡是比給定元素值大的所有元素,都作為該元素的子元素排列在該元素的左子樹上;凡是比給定元素值大的所有元素,都作為該元素的子元素排列在該元素的右子樹上。這樣一來開發人員就可以使用和二分查找法類似的查找方式定位要查詢的元素,或者在插入一個新元素前定位到新元素將要進行插入的位置。
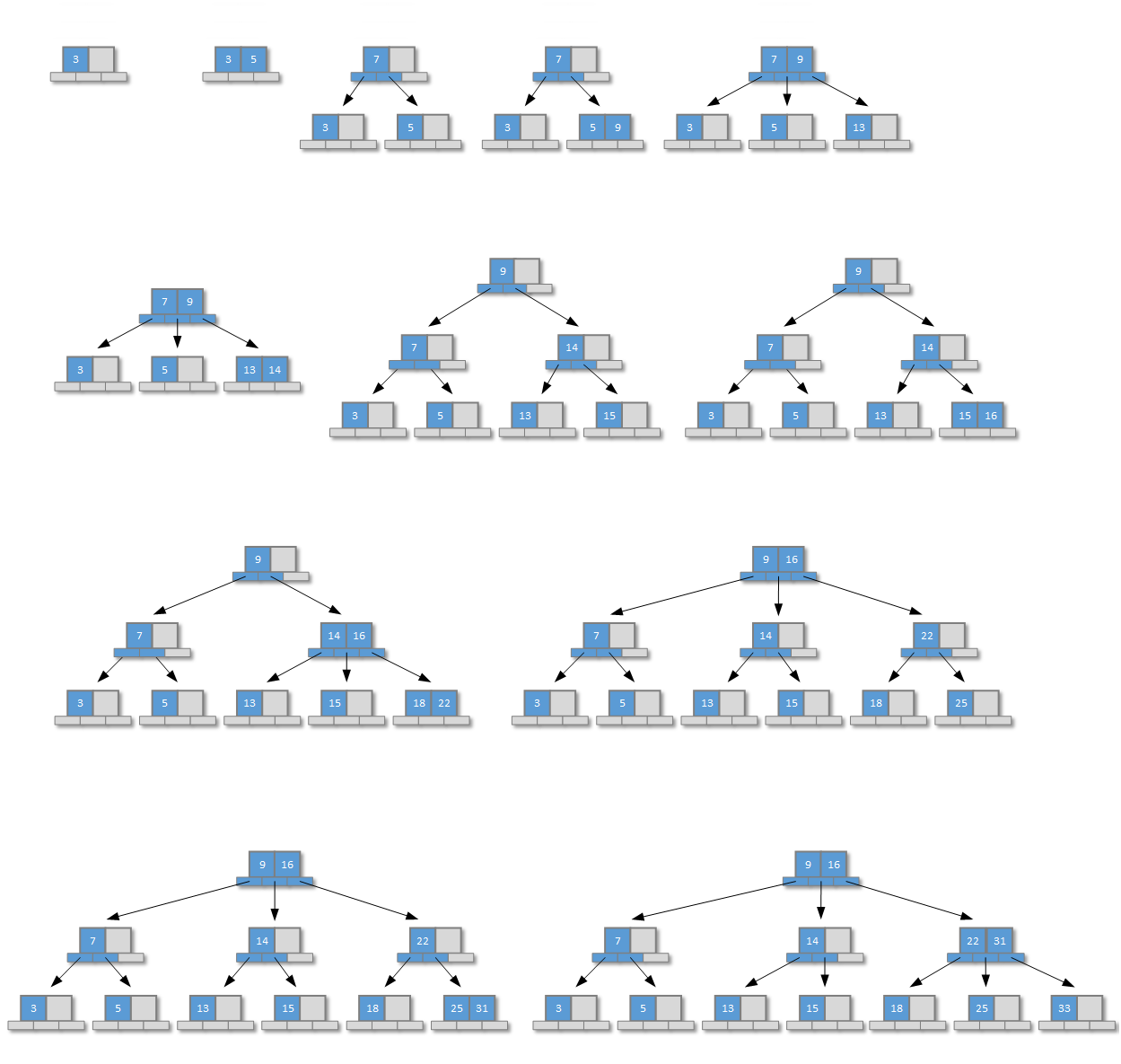
下圖演示瞭在B樹中依次添加元素時的分裂和節點間關聯過程,這些元素的值依次增大分別是:3、5、7、9、14、13、15、16、18、22、25、31、33。在實際應用開發中,雖然我們並不能保證插入B樹的元素值都是增加的,但是對B樹的插入操作過程卻是相同的(兩者的區別隻是定位的將要插入新元素的位置不一樣):
4-1-2、變體B+樹
B樹的優點很明顯:無論進行新元素的插入定位還是進行指定元素的查找,都可以快速完成這些定位/查找動作,其查詢性能的時間復雜度相當於二分查找法(O(log(n)))。但是B樹的缺點也很明顯,首先插入新元素時可能涉及到樹深度的改變,當然這個問題可以通過增加B樹的階數來解決。也就是讓每一個節點可以擁有更多的子節點,這樣就可以在存儲元素總量不變的情況下減少樹的理論深度,從而減少發生樹深度改變的情況,
另一個問題就稍微嚴重一些瞭,那就是B樹並不適合管理InnoDB引擎中的數據(這個在後文會進行說明)。還好B樹結構有一個變體結構,稱為B+樹。兩者最大的區別是,後者在B樹的結構基礎上擴展出瞭一個鏈表存儲結構,並且在樹的葉子節點對非葉子結點元素進行瞭冗餘存儲。如下圖所示:
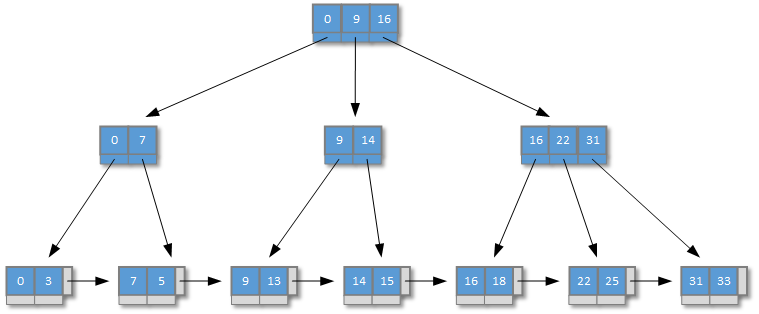
B樹和B+樹在新元素插入、元素刪除、元素查找等基本處理方式上沒有太大的區別。但是B+樹的兩個典型的結構變動剛好可以改進樹結構在InnoDB引擎中的應用:
由於B+樹的葉子節點存儲瞭非葉子節點的冗餘元素,所以我們可以在非葉子節點隻記錄某條數據的索引信息,而在葉子節點記錄具體的數據信息。那麼MySQL資料庫就可以在InnoDB引擎啟動時就加載B+樹的非葉子節點到內存特定區域,這樣做的最大好處是可以在內存空間和查找速度兩個維度上找到最好的平衡點。
特別註意的是,實際在InnoDB引擎中的B+樹結構,其葉子節點並不是存儲一行數據(要真是這樣,這顆B+樹不知道需要有多大。。。),而是和Data Page作為對應。在之前介紹InnoDB引擎的文章中已經說明過資料庫中Page的概念。Page是InnoDB引擎中最基本的數據操作單元,無論是InnoDB從磁盤上讀取數據還是改變數據,都以Page作為操作單位。同樣,InnoDB引擎中的索引結構也以Page為單位在葉子節點關聯具體數據。
另外B+樹在最底層將所有葉子節點串成瞭一個鏈表結構(不用擔心某個葉子節點沒有任何元素,因為B+樹遵循所有B樹的基本約束),這樣一來在進行數據查找時就可以使用表結構進行元素的依次查找,而無需再進行樹的遍歷操作。實際上在InnoDB引擎中每一個葉子節點都是一個Page信息,構成鏈表結構後就可以檢索每一個Page的上一個Page和下一個Page信息,這恰好也是InnoDB引擎中預讀功能的實現基礎。
4-1-3、InnoDB中的索引類型
InnoDB數據引擎使用B+樹構造索引結構,其中的索引類型依據參與檢索的字段不同可以分為主索引和非主索引;依據B+樹葉子節點上真實數據的組織情況又可以分為聚族索引和非聚族索引。每一個索引B+樹結構都會有一個獨立的存儲區域來存放,並且在需要進行檢索時將這個結構加載到內存區域。真實情況是InnoDB引擎會加載索引B+樹結構到內存的Buffer Pool區域。
聚簇索引(聚集索引)
聚簇索引指的是這樣的數據組織結構:索引B+樹的每個葉子節點直接對應瞭真實的Data Page。並且B+樹所有的葉子節點在最底層共同描述瞭一個可以直接進行行數據順序掃描的Data Page結構。如下圖所示:
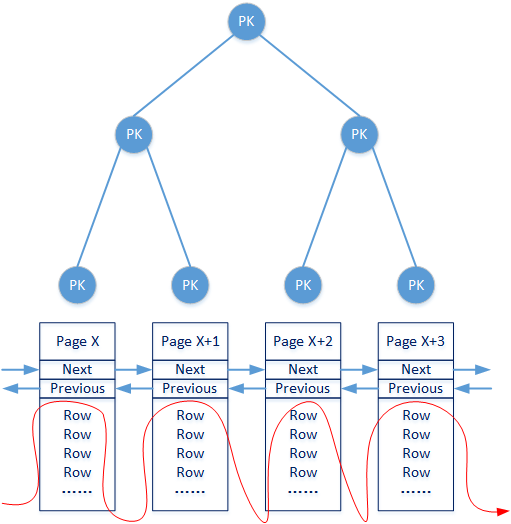
InnoDB引擎在組織索引和數據時,就是通過聚簇索引檢索具體Data Page。而聚簇索引B+樹的非葉子節點一般由數據表中的主鍵負責構造(當然也可能不是主鍵,這個後文會進行說明)。
主索引(主鍵索引/一級索引)
基於InnoDB引擎工作的每一張數據表都需要有一個主索引,這是因為上一段文字中提到的InnoDB引擎需要使用聚簇索引查找到具體的Data Page,而工作在InnoDB引擎下的數據表有且隻有主索引采用聚簇索引的方式組織數據。也就是說主索引B+樹的葉子節點都對應瞭真實的Data Page信息。
主索引在數據表的索引列表中使用PRIMARY關鍵字進行標識,一般來說是數據表的主鍵字段(也有可能是復合主鍵)。如果開發人員刪除瞭InnoDB引擎中某張數據表的主索引,那麼這個數據表將自行尋找一個非空且帶有唯一約束的字段作為主索引。如果還是沒有找到那樣的字段,InnoDB引擎將使用一個隱含字段作為主索引(ROWID)。
B+樹的構造特性在這裡就得到瞭充分利用,因為隻需要將主索引B+樹的非葉子節點加載到內存中。當檢索請求需要讀取某一個具體的Data Page時,再從磁盤上進行讀取。還記得在之前的文章中提到的預讀操作嗎?B+樹最底層葉子節點組成的鏈表結構,讓InnoDB引擎能夠輕松進行臨近的Data Page的讀取——如果參數設定瞭需要那樣做的話。
非聚簇索引(非聚集索引)
非聚族索引首先也是一顆B+樹,隻是非聚簇索引的葉子節點不再關聯具體的Data Page信息,而是關聯另一個索引值。InnoDB引擎下工作的每一個數據表雖然都隻有一個聚簇索引,那就是它的主索引。但是每一張數據表可以有多個非聚簇索引,而後者的葉子節點全部存儲著對應的數據主鍵信息(或者其它可以在聚簇索引中進行檢索的關鍵值)。
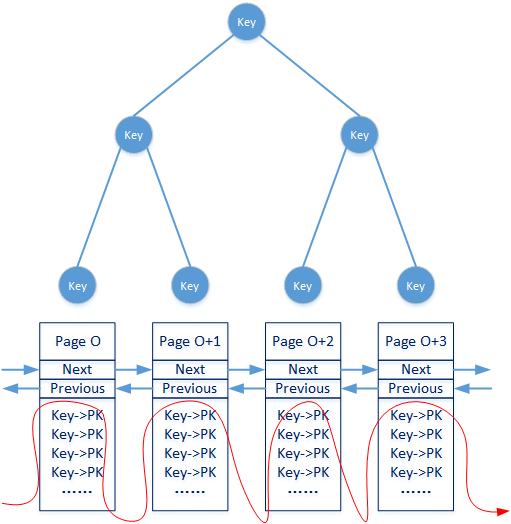
註意上圖所示的B+樹的葉子節點不再關聯具體的Data Page信息,而隻是關聯瞭構成聚簇索引非葉子結點的主鍵信息。
非主索引(輔助索引/二級索引)
數據表索引列表中除去主索引以外的其它索引都稱為非主索引。非主索引都是使用非聚簇索引方式組織數據,也就是說它們實際上是對聚簇索引進行檢索的數據結構依據。
例如當開發人員創建瞭一個以字段A作為索引的非聚簇索引結構,並且在SQL中使用字段A作為查詢條件執行檢索時。InnoDB會首先使用非聚簇索引檢索出對應的主鍵信息,然後再通過主索引檢索這個主鍵對應的數據。
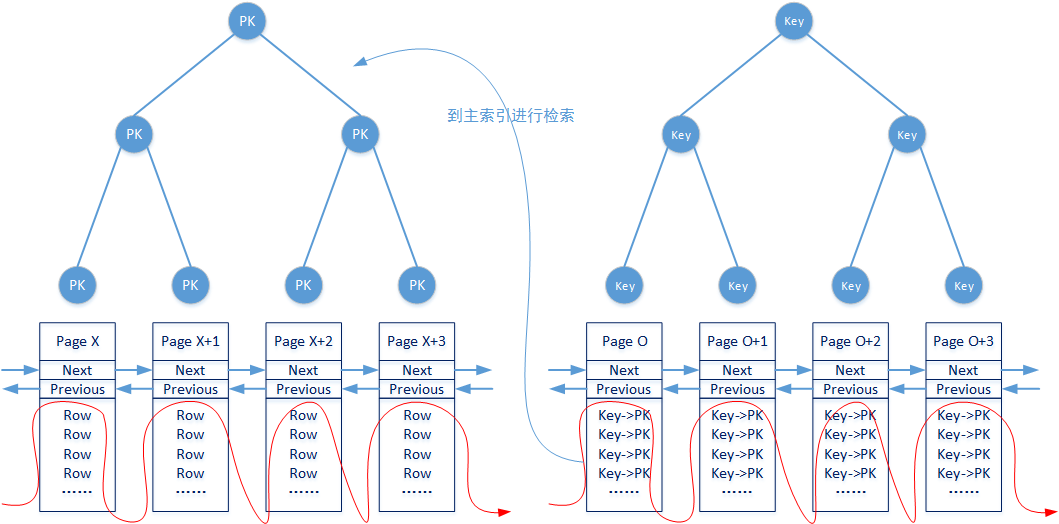
關於索引和執行計劃調整的介紹,將在下一篇文章中提到。
4-2、Query Cache
為瞭加快查詢語句的執行性能,從MySQL早期的版本開始就提供瞭一種名叫Query Cache的緩存技術。這個緩存技術和技術人員使用哪種資料庫引擎無關,它完全獨立工作於各種資料庫引擎的上層,並使用獨立的內存區域。
Query Cache的工作原理描述起來也比較簡單,當某一個客戶端連接(session)進行SQL查詢並得到返回信息時,MySQL資料庫除瞭將查詢結果返回給客戶端外,還在特定的內存區域緩存這條SQL查詢語句的結果,以便包括這個客戶端在內的所有客戶的再次執行相同查詢請求時,MySQL能夠直接從緩存區返回結果。這裡有兩個關鍵點需要明確:
什麼是“相同的查詢語句”?Query Cache使用K-V結構對查詢結果進行記錄,其中的K就是查詢語句本身(當然還要附加上諸如database name這樣的關鍵信息)。所以“select * from A”和“select * from a”這樣的語句將被看成是兩條不同的查詢語句。“select * from A”和“select * from A”也將被視為兩條不同的查詢語句(空格數量不一樣)。
怎樣避免“緩存數據不一致”的問題?
一旦被緩存的查詢結果所涉及的數據表發生瞭“寫”操作,那麼無論“寫”操作本身是否影響到被緩存的數據,涉及到數據表的所有緩存數據都將被清除。這種簡單暴力的處理方式,不僅繞過瞭數據一致性問題,還節約瞭寶貴的時間——因為在大多數資料庫應用中,讀請求是遠遠多餘寫請求的。如果您所在團隊開發的應用會使MySQL資料庫讀寫請求比例達到或查過1:1,那麼使用Query Cache就沒有什麼意義,建議直接關閉。
4-2-1、Query Cache基本設置
您可以通過“show variables like ‘query_cache%’”語句查詢當前為MySQL服務設定的和Query Cache相關的參數值。
# show variables like 'query_cache%';
query_cache_limit 1048576
query_cache_min_res_unit 4096
query_cache_size 0
query_cache_type OFF
query_cache_wlock_invalidate OFF
這些設置參數的設定可以簡單描述如下:
query_cache_size:這是參數設置瞭MySQL服務中Query Cache的全局大小,單位為byte。該參數在MySQL version 5.5及以後版本中的默認值都為0,也就是說如果在這些版本中要使用Query Cache則需要自己設置Query Cache的大小。query_cache_size不應該這是太大(最大支持256M),這是因為當某張數據表進行寫操作時,MySQL服務需要從Query Cache抹去的相關數據也就越多,反而會增加耗時。query_cache_size設置為33554432(32M)是比較好的。
query_cache_limit:該參數設置單條查詢語句允許緩存到Query Cache中的最大結果容量值,1048576(1M)是它的默認值。也就是說如果查詢語句返回的查詢結果集合大於1M,則這個查詢結果集合不會緩存到Query Cache區域。
query_cache_min_res_unit:該參數設置Query Cache每次分配內存的最小大小,默認值為4096(4KB)。
query_cache_type:註意,既是單獨設置query_cache_size為0,也不會使MySQL服務關閉Query Cache功能。一定要設置query_cache_type參數為0(OFF)才行。另外當該參數值為1(ON)時,代表開啟Query Cache功能,此時必須在SQL查詢語句中明確使用SQL_NO_CACHE,才能關閉這條查詢語句的Query Cache功能;該參數的值還可以為2(DEMAND),此時隻有當SQL查詢語句明確使用SQL_CACHE關鍵字,才能讓這條查詢語句使用Query Cache功能。
query_cache_wlock_invalidate:該參數設置Query Cache中數據的失效時刻(非常重要)。如果該值為1(ON),則在數據表被寫鎖定的同時該表中數據涉及的所有Query Cache都將失效;如果該值為0(OFF),則表示在數據表寫鎖定的同時,Query Cache中該數據表的相關數據都還繼續有效。
您還可以通過“show status like ‘Qcache%’”語句查詢當前MySQL服務中Query Cache的工作狀態
# show status like 'Qcache%'
Qcache_free_blocks 0
Qcache_free_memory 0
Qcache_hits 0
Qcache_inserts 0
Qcache_lowmem_prunes 0
Qcache_not_cached 0
Qcache_queries_in_cache 0
Qcache_total_blocks 0
各位讀者看到以上示例中所有和Query Cache相關的狀態值都為0,這是因為在演示的MySQL服務中默認關閉瞭Query Cache功能(主要是設置瞭query_cache_type的值為0)。不過以上展示的Query Cache狀態信息中一些狀態項還是要進行說明:
Qcache_free_memory:該指標說明瞭當前Query Cache專用內存區域還有多少剩餘內存。
Qcache_hits:該指標說明當前Query Cache從MySQL服務啟動到現在的命中次數。
Qcache_lowmem_prunes:該指標說明因為Query Cache內存不足而被清除的查詢結果數量。
其它的狀態項可參見MySQL的官方文檔《The MySQL Query Cache》
4-2-2、Query Cache的局限性和使用建議
為什麼MySQL Version 5.5及以後的版本會默認關閉Query Cache功能呢?這至少說明官方並不建議在任何場景下都是用Query Cache功能,甚至是大多數場景下。首先,Query Cache存在功能局限性:
早期版本(Version 5.1)的Query Cache功能並不支持變量綁定,也就是說類似“select * from A where field = ?”這樣的SQL查詢結果不會被放入Query Cache中。
存儲過程、觸發器等基於資料庫引擎類型工作的特定功能,如果其中使用瞭查詢語句,這些查詢語句的結果也不會放入Query Cache中。
復雜的SQL查詢中,往往包含多個子句。這些子句的查詢結果能夠被放入Query Cache中。但是用於包含這些子句的外部查詢結果卻不能放入Query Cache。
以上提到的Query Cache功能局限性在每次MySQL版本升級的過程中,MySQL開發團隊都逐漸進行瞭調整,所以這寫功能性限制並不是什麼太大的問題。例如以上說到的在存儲過程中的SQL查詢不會加入到Query Cache中,這個實際上就不是什麼大問題,目前來看業務系統中業務邏輯處理部分還都是放在上層業務代碼中來解決,使用復雜存儲過來處理業務邏輯的情況不多見。MySQL官方默認關閉Query Cache主要還是因為Query Cache的性能局限性:
“Waiting on query cache mutex”這種錯誤是典型的使用Query Cache不當所引起的錯誤。由於Query Cache設計的暴力清除策略,導致隻要有數據表進行寫操作,Query Cache中和這個數據表相關的所有結果都要失效的現象。所有需要從Query Cache中讀取相關數據的客戶端session就要等待數據清除完畢,所以就會出現以上錯誤提示。
如果這時query_cache_size設置得過大,反而會加劇這個問題的嚴重程度。因為過大的Query Cache區域意味著可能存儲瞭和這個被寫操作關聯的數據表的更多查詢結果集,也就需要更多時間去清除數據。
如果這張數據表又是寫密集度非常高的數據表,那麼這個問題會更加嚴重。因為Query Cache中相關數據會被頻繁的擦除、重寫。客戶端session也會不停的進入鎖定等待狀態。
在實際業務應用中,筆者並不建議直接關閉Query Cache。而是建議在將query_cache_type參數設置為2(DEMAND)並分配不大的內存總空間(query_cache_size 設置為16MB足夠瞭)的前提下,由業務層代碼顯式控制Query Cache的使用。
隻有滿足以下所有特點的SQL查詢操作才建議顯示開啟Query Cache功能:寫操作並不密集的數據表、讀寫操作比最好大於10:1(或者根據讀者自己的業務特性規定的更大比值)。畢竟隻有業務層才清楚哪些數據表的讀寫操作比大於10:1,並且寫操作並不時常進行。而滿足以上操作特性的數據表通常都是基礎性碼表:例如行政區域表、電話分區表、身份證分區表、車輛號牌表。
對於復雜的SQL查詢、讀寫比不大的數據表、寫操作頻繁或者寫操作並發特別大的數據表並不建議開啟Query Cache功能。例如訂單表、庫存物品表、車輛承運表、評論信息表等業務寫操作頻繁的數據表。